Literature pipeline: a shared discovery layer across six research projects
Try it: Repository · MIT licensed · CI green on Python 3.11-3.13 (Ubuntu + Windows) · 83/83 tests passing.
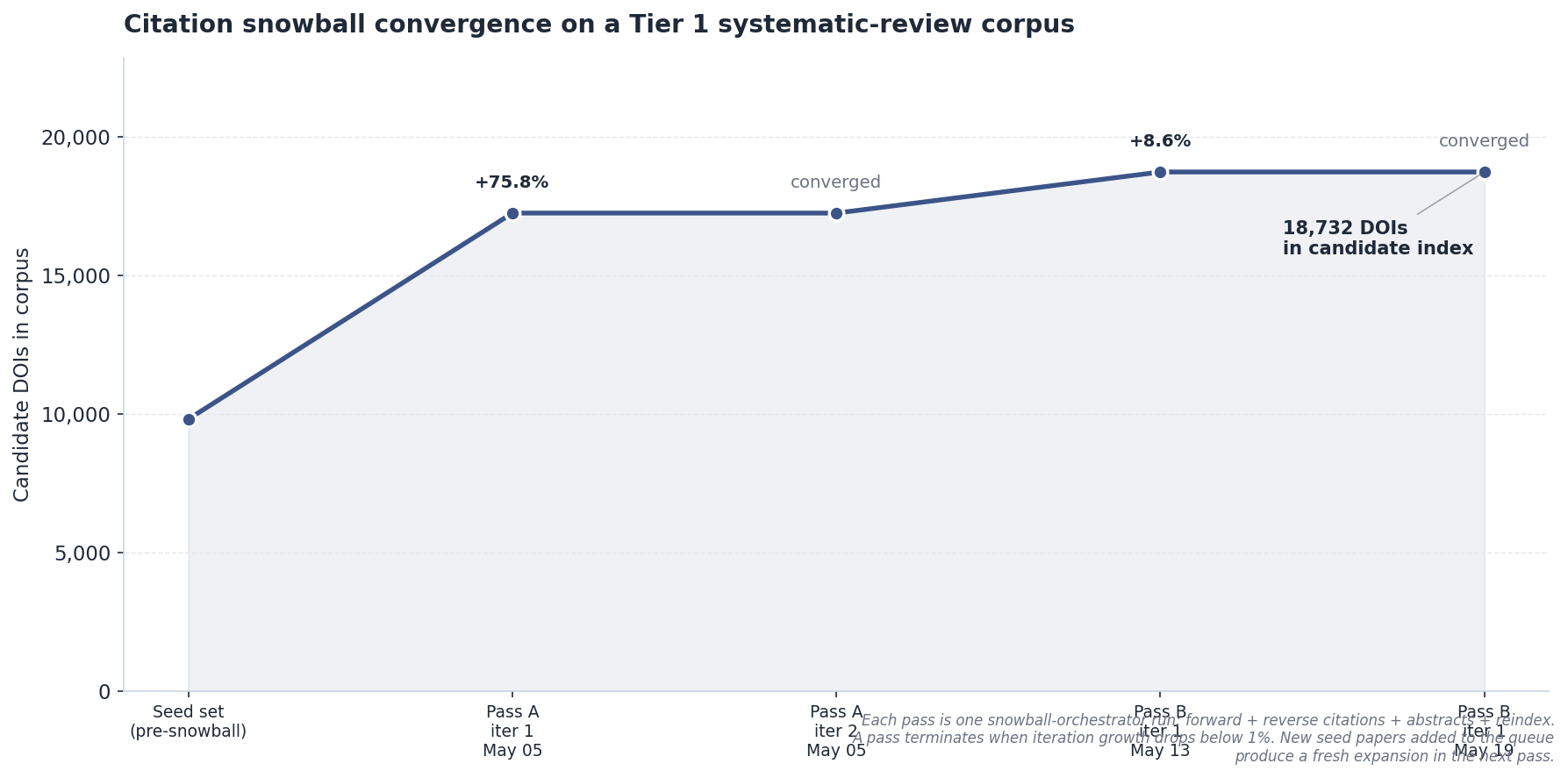
snowball.py run (forward citations + reverse citations + recommendations + abstracts + reindex); a pass terminates when iteration growth drops below 1%. Adding new seed papers to the queue triggers a fresh expansion in the next pass.The problem
A working researcher’s literature stack is fragmented. Unpaywall finds the open-access copy when there is one, PubMed Central holds the JATS XML for the NIH-funded subset, arXiv and bioRxiv carry the preprints, EndNote or Zotero stores the citations, and the PDF library on disk drifts out of sync with all of them. Across multiple projects the same paper gets pulled twice with different filenames, the citation graph never gets walked, and “what do I have on heat acclimation across these three projects” is not a question you can answer without grep and luck.
The pipeline started inside one project. A wheel-reinvention audit in April 2026 mapped each of its nine capability buckets to its closest open-source replacement, confirmed that no off-the-shelf tool did the whole job, and the pipeline got promoted to portfolio level. It now serves six projects from one shared workspace.
What it is
Roughly forty Python scripts living at the portfolio level, with a per-project queue file as the contract. A downstream project writes lit_pull_queue.csv with DOIs and a destination directory. A maintainer session runs sweep.py, which walks every project’s queue, cascades Unpaywall to PMC to preprint servers (arXiv, Europe PMC preprints, OSF, bioRxiv), drops PDFs into the right directory, and emits a .ris sidecar plus a JATS-derived JSON sidecar alongside each PDF.
A central DuckDB index (portfolio.duckdb) is the single source of truth for “what we have” and “what we should fetch next.” Schema v2 (May 2026) separates paper_metadata (one row per DOI) from paper_locations (which projects have a given PDF), with views for top candidates, cross-project duplicates, and per-project coverage. Citation walking lives at the same layer: snowball.py runs forward citations (Semantic Scholar), reverse citations (PDF parse with sidecar fallback), recommendations, and abstract enrichment in one command, then re-indexes.
The pipeline registry distinguishes Tier 1 projects (full systematic-review build: discovery, fetch, tables, text dumps, reports) from Tier 2 (library only). Promotion is opt-in, never automatic.
Current state (as of 2026-05-16): 17,617 unique DOIs indexed, 368 with full PDFs, 9,834 abstracts enriched, 21,104 citation edges. Six active consumers: one Tier 1 systematic-review project (the getpaid corpus that backs rtSD Explorer and the Banister Constellation) and five Tier 2 library-only projects spanning biomedical data analysis, thermophysiology, applied sport science, and wearable clustering.
What’s actually novel
The wheel-reinvention audit produced a comparison table that ships with the repo. Of the nine capability buckets, four have credible open-source alternatives (unpywall, paperscraper, pubget, s2orc-doc2json); five have no comparable tool. The genuine contributions:
- Unpaywall +
citation_pdf_urlmeta-tag HTML fallback for OA landing pages that don’t serve a direct PDF (unpywallis archived as of 2024) - MathML→LaTeX with source preservation.
s2orc-doc2jsonraisesNotImplementedError('Display formula!')on display math. The pipeline vendorspy-mathml-to-latex(MIT) and wraps it with a sidecar that preserves the source MathML informulas[i].mathml_inputso callers can re-process with their own tooling if the converter fails for their corpus. Common cases (fractions, sums, integrals, Greek, sub/sup) round-trip cleanly; complex matrices and custom operators may need manual cleanup, and the sidecar makes that recoverable - Citation walking with sidecar fallbacks (forward + reverse + recommendations), a bespoke wrapper over Semantic Scholar with a References-section parser that cascades sidecar JSON → text dump → fitz PDF parse
- Cross-project DuckDB index with
top_candidatesview ordered by seed-pointing count, surfacing the next-best-to-fetch across the whole portfolio - End-to-end orchestration:
sweep.py,snowball.py,pipeline_check.py,audit_portfolio.py. Nobody else has bothered to write the glue
The PMC and preprint stages overlap meaningfully with paperscraper. The README says so honestly and identifies them as the drop-in swap candidates if you’d rather depend on a maintained library than carry the wrappers.
What I learned from negative results
In May 2026 the pipeline got an experimental OpenAlex Tier 2 fetcher (~250 LOC) on the theory that OpenAlex’s broader green-OA repository coverage might rescue some of the residual papers Unpaywall and PMC couldn’t reach. Test corpus: 68 DOIs from getpaid’s needs_manual_pull.csv.
Result: zero net new downloads. Of the 68, 57 came back oa_status=closed (genuinely no OA copy exists), and 11 returned publisher landing URLs that all returned 403 to anonymous requests, including one institutional repository. The OpenAlex Tier 2 was not shipped. The README now documents the institutional-access boundary explicitly: in a typical biomedical corpus, expect roughly 5-15% of papers to be genuinely paywalled to anonymous traffic. Those land in the residual report with a bucket tag (PAYWALL, OA_NO_URL, PMC_GATED_WEB_ONLY) and the legitimate workflow is institutional library plus backfill_ris.py for metadata.
The lesson lives in the changelog as a one-line warning: don’t re-invest in OpenAlex, CORE, or Scholar wrappers without measuring the corpus-specific lift first. The cautionary baseline is now part of the artifact.
Where it fits
The pipeline is the discovery layer underneath several other projects on this site. The rtSD Explorer case study’s getpaid companion uses the pipeline’s top_candidates view to surface the priority-ordered queue for the Banister fitness-fatigue literature. The Banister Constellation citation graph is built directly from the pipeline’s cites edges and paper_metadata rows. The Tier 2 projects use it as a library-only consumer; the contract is the same.
The most recent extension (2026-05-16) wires Anthropic’s Consensus MCP into the open-world variant of the literature-session SOP as a Stage 0, closing the gap where the open-world flow previously required hand-orchestrated web search and manual DOI extraction. A 6-query test pass returned 60 candidates with 23% overlap to existing libraries and roughly 34 worth queueing.
The forward plan is staged. Stage A is an embedding-similarity ranking layer using SPECTER2 plus DuckDB’s vss extension, so the 17k candidate DOIs can be ranked by relevance to a project’s seed set without LLM tokens. Stage B is a local retrieval-augmented generation layer (Ollama + Qwen 2.5 7B + paper-qa2 or a DIY scaffold), gated on a hardware confirmation. Stage C wraps the whole thing as an MCP server so any Claude Code session in any project can call it natively. The roadmap ships with the repo.
Try it
Two minutes from clone to your first PDF.
git clone https://github.com/JacobBowie/literature-pipeline.git
cd literature-pipeline
pip install -r requirements.txt
export LITPIPE_EMAIL="you@example.org"
cp projects.json.template projects.json
# Edit projects.json with one Tier 2 entry pointing at any directory.
mkdir -p ~/my_review/literature
cd ~/my_review
cat > lit_pull_queue.csv <<'EOF'
doi,title,authors,year,destination,notes
10.1152/jappl.1972.32.6.812,Predicting rectal temperature,Givoni B; Goldman R,1972,literature/,baseline
EOF
python /path/to/literature-pipeline/sweep.py --project my_review --dry-run
python /path/to/literature-pipeline/sweep.py --project my_review
# → ~/my_review/literature/1972_Givoni_PredictingRectalTemperature.pdf
# → ~/my_review/literature/1972_Givoni_PredictingRectalTemperature.fulltext.json
# → ~/my_review/literature/1972_Givoni_PredictingRectalTemperature.risThe same project registry feeds every downstream tool. snowball.py --until-convergence walks the citation graph until candidate growth drops below one percent. audit_filenames.py --execute cascades CrossRef-canonical renames across PDFs and their sidecars. Full command reference and DuckDB sample queries in the README.
What it is not
Not a paywall bypass. Not a Sci-Hub wrapper. Not a startup product. It is research workflow infrastructure that compounded over a year of doing science and got tired of doing the same lookup three times. Every request identifies itself by mailto contact per API ToS. The institutional-access boundary is a fundamental property of “no auth, no proxy” tooling, not a limitation we’re going to fix.
Source and citation
- Repository: github.com/JacobBowie/literature-pipeline
- License: MIT
- Citation: see
CITATION.cffin the repository - Forward plan: ROADMAP.md
- State snapshot: CURRENT_STATE.md
If the pipeline is useful in your own work, please reach out at jacob.bowie2@gmail.com. The Stage A through Stage C roadmap items are open to collaboration, particularly the local-RAG hardware path.